Redis Cluster 와 장애 - (1) Redis는 어떻게 Cluster를 만드는가?

해당 글은 Redis Cluster에 대한 기본적인 이해를 필요로 합니다.
기본적인 Redis Cluster의 구조와, Hash Slot 에 대해 알고 있어야 하며, 추가적으로 Redis Cluster를 구축하기 위해 어떤 명령어를 사용하는지도 알아두면 좋습니다.
개인적으로 느끼는거지만, 서비스의 장애를 분석하거나 대비하는 과정에서 얻는 것이 더 많은 것 같다.
단순히 이론적으로 이게 뭐가 좋은지, 이게 뭐가 안 좋은지 를 공부하는 것을 넘어서, 실제 장애를 맞아보거나 (물론 그때는 괴롭지만... ㅠㅠ) 사례를 듣고 분석하게 되면 실제로 우리가 간과했던 것이 어떻게 치명적으로 돌아오는지 알 수 있고, 이걸 분석하는 과정에서 사용하는 기술에 대한 내부적인 분석도 할 수 있기 때문이다.
대표적인 예시가 Redis인 것 같다. 부서에서도 장애를 맞아봤고, 다른 부서의 장애 사례를 공유받으면서 얻은 것들이 많았기 때문이다.
이번엔 그 중에서 가장 많이 발생했던 Redis Cluster 와 관련한 이야기를 해보려고 한다. 다만 원래는 FAILOVER 를 수행해서 �문제를 해결할 수 밖에 없던 다양한 케이스를 들고, 내부를 파보려고 했으나 이렇게 되면 아무도 글을 이해 못할 것 같아서 (...) 해당 내용은 후속 글로 작성해보기로 하고, 이번엔 Redis Cluster를 구축하는 단계에서부터 꼼꼼히 살펴보려고 한다.
(*블로그의 컨셉과 달리 개념적인 이야기를 많이 하게 되어서 다소 아쉽지만.. 2편을 위한 빌드업이라고 생각하고...)
RESP
RESP는 REdis Serialization Protocol 의 줄임말로, Redis 클라이언트가 Redis 서버와 데이터를 주고 받기 위한 목적으로 사용하는 프로토콜이다.
Redis 1.2 부터 RESP가 도입되었고, 2.0 부터 RESP2, 6.0 부터는 부분적으로 RESP3이 도입되었다.
우리가 이 글을 이해하기 위해 프로토콜을 매우 빠삭하게 알 필요는 없지만, 기본적인 형태와 구조만 이해하면 Redis를 이해하는데 충분히 많은 도움이 된다. (만약 RESP를 전부 빠삭하게 알고 있다면, Redis 클라이언트가 Redis 서버에 연결한 것 처럼 속이게 할 수 있는 가짜 Redis 서버도 만들 수 있다!)
| 타입 | Prefix | 예시 | 설명 |
|---|---|---|---|
| Simple String | + | +OK\r\n | 짧은 문자열 (성공 응답 등) |
| Error | - | -ERR wrong type\r\n | 에러 메시지 |
| Integer | : | :1000\r\n | 정수 값 |
| Bulk String | $ | $3\r\nfoo\r\n | 길이 지정된 문자열 |
| Array | * | *2\r\n$3\r\nGET\r\n$3\r\nkey\r\n | 여러 항목을 묶은 배열 |
모든 데이터는 CRLF(\r\n)로 구분된다.
## Client 가 Server에 보내는 요청 (SET foo bar)
*3\r\n
$3\r\n
SET\r\n
$3\r\n
foo\r\n
$3\r\n
bar\r\n
## Server는 이를 ["SET", "foo", "bar"] 로 인식함
+OK\r\n
우선 너무 깊게 분석하지 말고, 이정도만 알아두자. (이후, 딱 한 군데에서 이걸 다시 언급할 것이다.)
Redis는 어떻게 Cluster를 생성하는가?
사실 어지간한 Cluster 구성이 그렇지만, Redis 또한 Cluster 생성을 위해선 다소 복잡한 Handshake 과정을 거친다.
다만 우리는 Slave 노드 추가시엔 redis.conf 만 수정했고, Cluster 추가를 희망하는 경우엔 --cluster add-node 등을 사용해서 노드를 추가했을 것이다.
그렇다면, 내부적으로는 무슨 과정을 거칠까?
PING
- TCP Handshake 등을 제외한다면, 가장 먼저 하는 것은
PING명령어를 통해 해당 서버 및 포트에 Redis가 돌아가고 있는지, 접근이 가능한지 등을 확인한다. - 사실상의 Health Check 목적을 위한 명령어이고, 클러스터 구축이나 (
CLUSTER MEET를 쓰던, Slave로 추가되던) 클러스터 내부에서의 지속적인 헬스체크 등에서도 사용된다. (결국은, 우리가 해당 명령어를 직접 호출할 일은 사실상 없��다.)

처음 Redis 공부했을 땐 클러스터고 뭐고 아무것도 몰라서, 이 명령어는 그냥 심심해서 넣은 줄 알았다...
Master 노드 추가 (Hash Slot 노드)
-
보통은 cluster를 생성할 때는 redis-cli 에서
--cluster계열 명령을 쓰다보니 간과할 수 있지만, 앞에서 설명했던 것 처럼 결국 RESP 기반으로 Redis는 통신을 할 것이고, 그걸 기반으로 머리를 조금만 굴려보면 결국 이미 Redis에 존재하는 명령어 셋을 주고 받을 것이라는 예측을 할 수 있다.- 실제로는 아래와 같은 명령어가 내부에서 호출된다고 생각하면 된다.
-
클러스터에 합류하기 위해,
CLUSTER MEET를 사용한다.- Redis Cluster에 대해 공부했다면, 아래와 같은 Mesh 구조를 갖고 있음을 인지할 것이고, 즉 아무 노드에나 자신을 MEET 해도 자연스럽게 Cluster 내 모든 노드와 정보가 공유된다고 생각하면 된다.
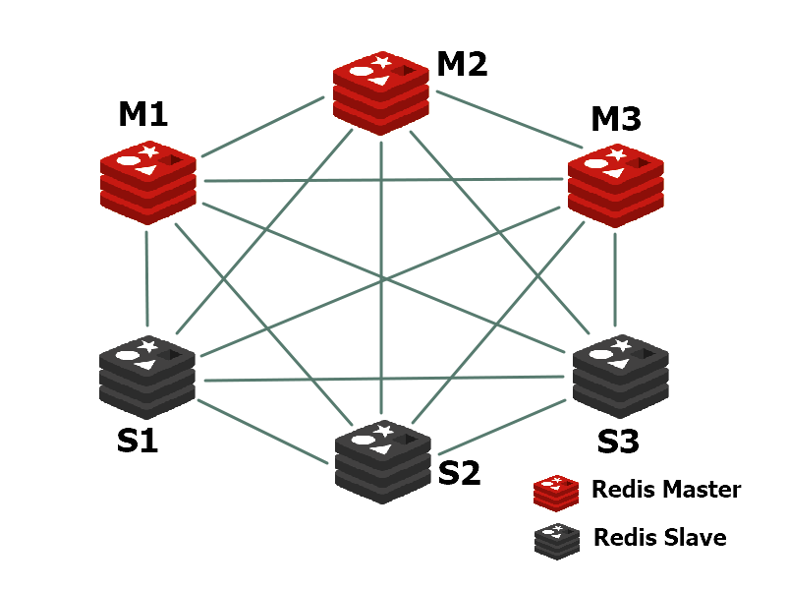
-
앞에서 PING 을 언급했던 것 처럼, 노드들은 Mesh 의 노드들에 대해
PING을 주고 받고, Gossip 프로토콜을 활용하여 서로 다른 노드들의 상태들을 전파한다. -
여기서 중요한 건, 합류만 된 것이지 Hash Slot을 할당받지 못 했기 때문에, Mesh 에 합류는 되어 있지만 데이터를 전달 받지는 않는다.
-
신규 클러스터인 경우,
CLUSTER SET-CONFIG-EPOCH이라는 명령어를 호출하여 epoch 을 설정하나, 이에 대한 내용은 해당 포스트에선 생략한다.- 해당 값은 내부 Gossip 프로토콜에서 활용하기 위한 값으로, Raft 알고리즘의 term 과 유사한 의미를 가진다. epoch 을 이해하는 것이 Redis Cluster 구조를 이해하는 것에 도움이 될 순 있겠지만... 너무 분량이 폭발할 것 같아 제외한다.
-
그 후
CLUSTER ADDSLOTS을 호출하여 0-16383 까지의 슬롯을 n 등분하여 배정한다.
번외 - Vote-Only Node가 가능한가?
글을 작성하다보니 갑자기 궁금해 져서 좀 찾아본 내용이다.
MongoDB Arbiter, ElasticSearch Voting Only Node 등, 이미 수많은 분산형 데이터베이스에는 Vote-Only Node가 존재한다. 해당 노드는 데이터가 저장되진 않지만, 일부 노드의 장애로 새로운 마스터 선출이 필요한 상황에서 투표만 하기 위한 목적의 노드인 것이다. (보통 과반수 문제에서 자유로워지��기 위해 사용한다.)
앞에서 말했듯이 CLUSTER ADDSLOTS를 호출하지 않으면 Master 노드임에도 데이터를 할당받지 못하니 사실상 Vote-Only 처럼 사용할 수 있지 않을까?
이건 진짜 검색을 해도 답이 없다보니, 작정하고 코드를 뒤져봤다.
/* Vote for the node asking for our vote if there are the conditions. */
void clusterSendFailoverAuthIfNeeded(clusterNode *node, clusterMsg *request) {
clusterNode *master = node->slaveof;
uint64_t requestCurrentEpoch = ntohu64(request->currentEpoch);
uint64_t requestConfigEpoch = ntohu64(request->configEpoch);
unsigned char *claimed_slots = request->myslots;
int force_ack = request->mflags[0] & CLUSTERMSG_FLAG0_FORCEACK;
int j;
/* IF we are not a master serving at least 1 slot, we don't have the
* right to vote, as the cluster size in Redis Cluster is the number
* of masters serving at least one slot, and quorum is the cluster
* size + 1 */
if (nodeIsSlave(myself) || myself->numslots == 0) return;
L10-L13의 주석을 번역하면 다음과 같다.
Redis Cluster의 클러스터 크기는 1개 이상의 Slot을 갖고 있는 노드의 수 이므로, 만약 Master 노드가 1개의 슬롯도 갖고 있지 않다면 투표권도 없고, Quorum 에도 포함되지 않는다.
즉 노드가 보유하고 있는 슬롯이 없다면, 사실상 클러스터의 구성원으로 보지도 않으니 Vote-Only 노드는 존재할 수 없다고 봐야한다.
Slave 노드 추가
Cluster를 구축할 정도의 환경이라면 당연히 Master와 함께 자연스럽게 Slave도 달아줘야 한다.
- 언제나
PING은 필요로 한다. CLUSTER REPLICATE <masterId>를 호출하여 slave를 등록한다.- 여기부터는 일반적인 레플리카 등록과 동일하다.
- Slave는 Master에게
REPLCONF를 호출하여 복제본 생성과 관련�한 메타데이터를 교환하고, 이후PSYNC를 통해 데이터 전달을 받는다.
Master 노드로 등록했다고 해도, 위에서 언급했듯이 슬롯을 할당받지 못하면 사실상 없는 노드랑 마찬가지라는걸 기억해보자. 즉, 할당받은 슬롯이 없다면 Master 노드라고 해도 CLUSTER REPLICATE를 호출해서 Slave로 전직할 수 있다.
PSYNC
오늘의 핵심 포인트 중 하나로, 사실상 Redis에서 Replication 을 수행하기 위해 반드시 필수적으로 알아야 하는 존재다.
결국 간단하게 말해서, Master 에게 데이터를 전달해 달라고 요청하는 것이다.
PSYNC <replid> <offset>으로 구성되어 있다.- 최초 연결시에는
PSYNC ? -1으로 Full Sync를 요청한다. 이 경우, Master는 RDB를 추출해 데이터를 전달한다. - 재연결인 경우엔 일반적으로 Partial Sync를 수행한다.
offset 이라는 것을 보면 알 수 있듯이, 어디까지 전달 받았음 을 요구하는 것을 알 수 있다.
offset의 정의를 정확히 이해하기 위해선, 이전에 진행했던 Redis 세미나에서 언급한 Replication 데이터 전달 방식을 알고 있어야 한다.
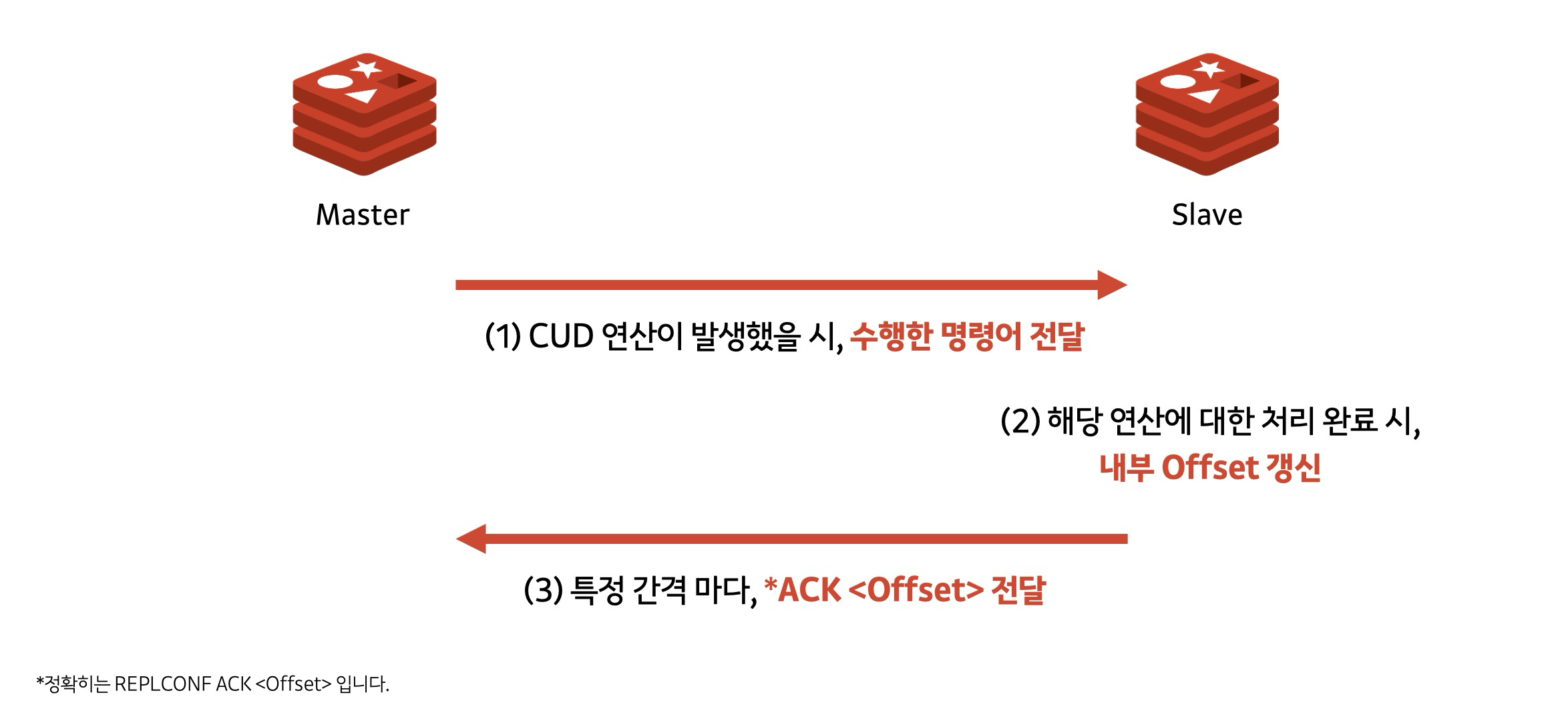
// SET foo 1을 Master에 호출 (Slave 전달 성공)
- Master -> Slave 로 SET foo 1 전달
- Slave는 해당 연산을 수행하고, 내부 Offset을 29로 갱신한다.
- 특정 간격 마다, REPLCONF ACK 29를 전달한다.
// SET foo 1을 Master에 호출 (Slave 전달 실패)
- Master -> Slave 로 SET foo 1 전달
- Slave는 해당 연산을 전달받지 못했으므로, 내부 Offset은 여전히 0 이다.
- 특정 간격 마다, REPLCONF ACK 0을 전달한다.
ACK 29 인 이유가 궁금할텐데, 이는 상단에서 언급한 RESP를 알면 설명이 된다. 결국 Master -> Slave로 명령을 전달할 때도 사용자가 보낸 명령을 RESP 형식에 맞게 인코딩할 것이고, 그 인코딩한 데이터의 길이가 29가 되기 때문에, 내부 Offset이 갱신되는 것이다.
결국 연결이 구축되고 나면,
- Master는 연산이 발생할 때 (마치 AOF 마냥) 자신의 Slave 들에게 명령어를 전달하고,
- Slave는 해당 명령을 수행하고 Offset을 갱신하여 Master에게 ACK를 전달하며,
- 자연스럽게 둘 사이에선 계속
PING이 호출될 것이다. (더 자세히 말하면repl-ping-replica-period주기로 보내고,repl-timeout안에 응답이 안 오면 헬스체크 실패로 간주한다.)
그런데, 데이터 전달이 원할하게 이뤄지지 않아 Master와 Slave의 Offset이 점점 벌어지게 된다면? 그럼 결국 명령어를 다시 보내서 재수행하는 것 보단, 아예 통짜 백업을 다시 전달하는 것이 편할 것이다. 그렇다면 offset이 벌어질 때 Redis는 이걸 어떻게 판단할까?
-
일단 TCP로 연결하는 Redis의 특성상, 전송 과정에서의 손실은 보통 TCP의 수많은 신뢰성 보장 도구로 인해 재전송이 이뤄질 것이다.
- 다만 Redis 자체는 재전송이라는 기능이 없다. 정말 운이 안 좋아서 TCP Buffer가 초과된다면, TCP 에서 Drop 이 발생하여 offset이 어긋난다고 해도 재전송을 하지 않는다.
-
offset이 벌어지는 것 자체는 full sync 트리거링에 영향을 주지 않지만, offset이 벌어지면 자연스럽게 발생하는 문제들로 인해 full sync가 유발될 수 있다.
-
네트워크의 특성을 고려하면 Master와 Slave 사이의 연결이 순간적으로 끊길 수 있는데, 이 때문에 보통은 backlog buffer 를 두어 그 시간동안 데이터가 유실되지 않도록 한다. (
repl-backlog-size) -
다만 offset이 너무 벌어져서 두 offset의 차이가
repl-backlog-size를 넘겨버리면 결국 데이터의 동기화가 불가능하다고 판단하여 full sync를 수행한다.-> 즉, 연결이 유지만 된다면
repl-backlog-size에 의해 full sync가 호출되는 경우는 없다. -
이외에도 단순 Master -> Slave 전달을 위한 별도의 버퍼가 존재하나,
client-output-buffer-limit를 초과하는 데이터가 쌓이는 경우 강제로 연결을 끊어버린다.-> 이것도 마찬가지로, 연결이 유지되는 동안엔 full sync를 호출하지 않는다고 생각할 수 있다.
-
client-output-buffer-limit
오늘의 핵심 포인트 두 번째.
redis.conf 파일을 보면 수많은 파라미터가 존재하는데, 사실 Redis를 다소 러프하게 쓰게 되면 이러한 파라미터에 대해 관심을 거의 갖지 않는다.
잠깐 해당 파라미터의 설명을 보고, 중요한 내용을 이야기 해 보자.
# The syntax of every client-output-buffer-limit directive is the following:
#
# client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>
#
# A client is immediately disconnected once the hard limit is reached, or if
# the soft limit is reached and remains reached for the specified number of
# seconds (continuously).
# So for instance if the hard limit is 32 megabytes and the soft limit is
# 16 megabytes / 10 seconds, the client will get disconnected immediately
# if the size of the output buffers reach 32 megabytes, but will also get
# disconnected if the client reaches 16 megabytes and continuously overcomes
# the limit for 10 seconds.
#
# By default normal clients are not limited because they don't receive data
# without asking (in a push way), but just after a request, so only
# asynchronous clients may create a scenario where data is requested faster
# than it can read.
#
# Instead there is a default limit for pubsub and slave clients, since
# subscribers and slaves receive data in a push fashion.
#
# Both the hard or the soft limit can be disabled just setting it to zero.
- hard-limit 에 도달하거나, soft-limit 에 도달하여 특정 시간이 지나면 연결을 강제로 해제한다.
normal은 큰 문��제를 보이지 않지만,pub-sub이나slave같은 경우는 제한이 중요하다.
자, 이제 위 내용을 다 합쳐보자.
- 현재 운영중인 Redis가 존재하고, Replication 을 사용하고 있다고 해보자.
- 순간적인 네트워크 이슈로 Slave 노드와 Master 노드의 연결이 해제되었다.
- 다만 트래픽이 많이 들어오는 서버라, 금방 Slave 노드와의 연결이 재개되었음에도
repl-backlog-size가 넘는 양의 데이터가 인입되었고, 결국 partial sync가 아닌 full sync 가 수행된다. - full sync가 수행되어야 하기 때문에
BGSYNC가 호출되고, RDB 파일을 생성한다. - RDB 파일이 생성중인 상황에 들어오는 데이터는
client-output-buffer에 저장된다. - RDB 파일을 전송하고 보니까,
client-output-buffer-limit가 초과되어 연결이 바로 끊긴다. (??????) - Slave 노드는 다시 Master 노드에 진입을 시도하게 되고, 무한 반복이 수행된다.
이렇게 되면 자연스럽게 Master 노드의 CPU 사용률은 100%로 치솟게 될 것이고, Master 노드의 부하로 Redis 전면 장애가 발생할 수 있다. 연결이 끊기는 건 발생할 가능성이 낮지만, (실제로 이 상황을 목격한 경험이 있는지라) 이에 대한 대비책은 충분히 필요하다.
결국 기본 설정을 그대로 사용하는 것이 아닌, 사용하고 있는 메모리나 트래픽 상황에 맞춰 파라미터 값을 적당히 조정해 줄 필요가 있는 것이다.
Cluster에 Master 노드가 추가된다고 데이터 편향 문제가 해결 될까?
뭔가 어디에 적고 싶다고 이전부터 생각을 많이 했었는데, 2부에는 도저히 못 적을 것 같아 여기에 짤막하게 적는다.
답만 빠르게 적으면, 그럴수도 있고, 아닐수도 있다. 라고 말할 수 있을 것 같다.
- 당연하지만 Hash 충돌로 인해 특정 Slot 범위에 키가 몰린다면, 노드가 추가되어 구간이 분산이 잘 된다면 어느정도 문제를 해결할 수 있을 것이다.
- 다만, 특정 key들의 hash slot의 위치가 완전히 똑같거나, 특정 key에 해당하는 value가 많다면 아무리 노드를 많이 추가해도 해결할 수 없다.
- 특히나, 리스트를 많이 쓰는 경우라면 후자는 필연적으로 발생할 수 밖에 없다.
그렇다면, 어떻게 하는게 좋을까? 사실 정말 간단하지만, 데이터를 분할하면 된다.
예를 들어서, dataList 라는 key가 있다고 해보자.
- key를
dataList:1,dataList:2,dataList:3으로 분리 - 애플리케이션에서 value를 넣을때, 자체 알고리즘을 사용하여 데이터를 3분할 (Java의
hashCode를 사용한다거나...) - 애플리케이션에서 데이터를 가져올 때, 전체 key를 순회하여 가져옴
그런데 이것도 잠깐 생각 해볼게 있다. key를 몇 개 만들어야 하는가? 만약 Cluster의 Master 노드의 수가 3이라고 해보자. 그렇다면 3개의 key로 분할했다고 해서, 3개의 key가 세 Master 노드에 균등하게 퍼질것이라는 보장이 있는가? 오히려 아닐 확률이 ��더 높을 것이다.
만약 key의 개수를 조금 늘려준다면, 약간이나마 더 퍼질 가능성이 존재할 것이다. 하지만 그렇다고 key를 한 2,000개 만들어버리면 그건 그거대로 문제가 될 것이다.
결국 key를 설계하는 관점에서 우리가 생각해보면 좋은 문제는, 어떻게 하면 최대한 모든 노드에 이 분산된 key가 하나 정도는 있도록 할 수 있을까? 라고 정의될 것이다.
대학때 확률론을 공부해봤다면, 쿠폰 수집가의 문제 에 대해 접해봤을 것이다. 배워본 적이 없다면 링크를 들어가도 저게 뭔 소리인가 싶을 것이다.
해당 문제를 우리가 이해하기 쉽게 각색해서 설명하면, 아래와 같다.
여러 종류의 씰이 있는 빵이 있다고 해 보자. 씰은 균등한 확률로 존재한다. (즉, 희귀 씰 같은 것 없다고 가정한다.) 이 때, 모든 씰을 최소 1개 이상 얻기까지 빵을 몇 개를 사야하는가?
도대체 이게 왜 Redis와 연관이 있는건가? 싶을텐데, 이 문제를 Redis와 비교해서 보도록 하자.
| 쿠폰 수집가 문제 | Redis Cluster |
|---|---|
| 쿠폰 종류의 수 n (빵에 들어간 씰의 종류 n) | 마스터 노드 수 n |
| 쿠폰 하나를 얻음 (빵을 까서 씰을 하나 얻음) | dataList:{idx} key 를 생성함 |
| 모든 쿠폰을 전부 수집 (모든 씰을 전부 수집) | 모든 노드에 최소 1개 이상의 키가 분배 됨 |
쿠폰 수집가 문제의 기본 공식은 아래와 같다.
이는 n개의 노드가 있고 k개의 키를 생성할 때 모든 노드가 최소 1개 이상의 키를 갖게 될 확률을 계산하는 공식이다.
다만 우리가 원하는 건 특정 확률 이상으로 모든 노드가 최소 1개 이상의 키를 갖고자 한다면, 생성해야 하는 key의 수 인 것이니, 식을 변형하면 아래와 같이 바뀐다.
계산은 우리가 하긴 어려우니, GPT에게 시키자 툴을 사용해서 돌리면, 대략 아래 같은 결과가 나온다.
| 노드 수 (n) | 목표 확률 (p) | 필요한 키 수 ((k)) (근사) |
|---|---|---|
| 3 | 0.95 | 8 |
| 3 | 0.99 | 11 |
| 6 | 0.95 | 17 |
| 6 | 0.99 | 24 |
| 10 | 0.95 | 28 |
| 10 | 0.99 | 39 |
실제로 업무에서는 노드의 수가 3개이고, 95% 확률로 키 분산을 목표하고 있으므로, dataList:0 ~ dataList:7 까지의 key를 생성하여 리스트 형식의 데이터를 관리하고 있다.
Redis Cluster 와 관련한 주절거림은 여기서 마무리 한다. 글 초반에도 언급한 것 처럼 이 글의 목적은 2편을 위한 준비운동이니, 2편에서 좀 더 자세한 이야기를 해보도록 하자.