Java 에서의 스케쥴링, 어떻게 가능한 것인가?

우리는 Spring 에서 스케쥴링 잡을 수행하기 위해, @Scheduled 라는 어노테이션을 사용하곤 한다.
@Scheduled(cron = "0/5 * * * * ?")
public void scheduledCron() {
// do something...
}
@Scheduled(fixedDelay = 1000)
public void scheduledfixed() {
// do something...
}
그런데 상식적으로 생각을 해보면, 정말로 Java가 1ms 단위까지 세밀하게 스케쥴링을 할 수 있을까? 라는 의문이 들 수 있다.
Java 이야기는 아니지만 Redis/MongoDB 같은 데이터베이스의 TTL 또한 ms 단위로 넣을 수 있지만 실제로는 ms 단위로 데이터 체킹 및 삭제가 이뤄지지 않기도 한다. Redis는 기본적으로 사용자가 데이터 조회 시도 전 까지 삭제를 수행하지 않고, (주기적으로 샘플링하여 체킹하고 지우는 작업이 존재하지만, 이는 보조적인 역할이다.) MongoDB는 TTL Monitor 스레드가 주기적으로 데이터를 확인하여 제거한다. (ttlMonitorSleepSecs 파라미터에 따라 다르지만, 디폴트는 1분이다. 즉, 최대 59초까지는 데이터가 안 지워질 수 있다.)
결국, 수많은 상용 기술들은 스케쥴링 처리가 우리의 의도 처럼 정확한 시간에 수행된다 라고 말하기 어려운데, Java는 어떨까?
Java가 스케쥴링을 지원하는 방법
가장 간단한 생각 - Thread.sleep()
Java의 Thread 는 대부분의 실제 동작을 OS에 위임하고 있다. 그렇기에, Thread.sleep(millis, nanos) 와 같은 메서드는 OS 스케쥴러에 이를 위임하게 되고, 자연스럽게 주기적인 작업을 수행하도록 유도할 수 있을 것이다.
try {
while (true) {
Thread.sleep(5000);
// do something...
}
} catch (InterruptedException e) {
e.printStackTrace();
}
다만, 이 방법이 스케쥴링 관점에서 효율적일까?
- 운영체제 관점에서, 인터럽트 된 스레드는 인터럽트 처리가 완료되어도 바로 실행되는게 아니라, 스케쥴링의 대상이 될 뿐이다. 즉, 5000ms 이후에 바로 실행됨이 보장되지 않는다.
- Real-Time 운영체제가 아닌 일반적인 운영체제의 경우, 정확한 Real Time 스케쥴링이 어렵다. (사실 이 부분 때문에라도, ms 단위 스케쥴링의 정확성을 보장하는 것은 거의 불가능하다.)
- 만약 우선순위를 설정했다면, (
Thread.setPriority()등으로) sleep 으로 시간 지연한 스레드가 바로 수행됨이 보장되지 않는다. - 스케쥴링 해야 하는 작업이 2개 이상이라면 각각의 작업에 대해 별도의 스레드가 필요한데, 각각의 스레드가 Sleep 처리가 되면 효율성이 매우 떨어진다.
사실 다른 사항들은 약간의 오차를 감안하고 넘어갈 수 있다고 쳐도, 마지막이 가장 치명적일 것이다. 스레드는 결국 자원을 차지하고 있기 때문에, 블로킹된 스레드의 수가 많으면 많아질 수록 프로그램의 전반적인 효율은 떨어질 것이다.
그렇기에, Java에서는 일반적으로 여러 작업을 병렬적으로 수행하기 위해서 스레드풀을 사용하고 있고, Java에서는 가장 기본적인 ThreadPoolExecutor를 상속한 ScheduledThreadPoolExecutor 를 통해 스레드풀을 사용하면서도 스케쥴링 잡을 수행할 수 있도록 구현하고 있다.
해당 도구의 구현을 좀 더 자세히 살펴보기 전, 위 글만 보면 생각할 수 있을 만한 “블로킹만 최소화 하면 좀 괜찮지 않을까?” 에 대한 해답을 알아보자.
방향 살짝 틀어보기 - Spin Lock
다음 코드를 보자.
var now = System.nanoTime();
while (true) {
var newTime = System.nanoTime();
if (newTime - now > 1_000) {
// do something
now = newTime;
}
}
이건 더 효율적인 솔루션일까?
결론만 말하자면 특정 상황에 따라 더 효율적일 수 있으나, Java 에선 대부분 비효율적이다.
- 이론적으로는 아주 정확한 타이밍을 모니터링 할 수 있지만, Java 언어 자체가 Hard Real Time 에 적합한 언어는 아니라, 완벽한 정확성을 보장할 수 없다.
- 참고: https://ko.wikipedia.org/wiki/%EC%8B%A4%EC%8B%9C%EA%B0%84_%EC%BB%B4%ED%93%A8%ED%8C%85
- 일반적인 Linux/Windows/MacOS 등의 OS는 RTOS (Real-Time OS) 가 아니라,
nanoTime()을 호출했을 시점에 바로 값을 리턴할거란 보장을 할 수 없다. 즉, 실제 해당 작업이 OS 스케쥴러를 통해 선택되고, CPU에 향하는 시점을 완벽하게 통제할 수 없다.
- 그와 반비례하여 자원 소모량이 엄청나게 올라간다. 하나의 작업마다 저렇게 Spin Lock을 걸어버리면, OS 및 JVM 스케쥴러에 악영향을 주기 쉽다.
ScheduledThreadPoolExecutor - Java가 내놓은 해결책
일반적으로, Java에서 병렬처리를 구현하기 위해선 ThreadPoolExecutor 를 사용하는 편이다. 그렇다면 ScheduledThreadPoolExecutor는 어떤 차이를 갖고 있을까?
사실, ScheduledThreadPoolExecutor는 ThreadPoolExecutor 를 상속한 클래스이다.
public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor implements ScheduledExecutorService
그런데, 이 클래스가 ThreadPoolExecutor 와 비교하여 어떤 차이를 갖고 있는가?
ThreadPoolExecutor는BlockingQueue<Runnable>구조 (즉, 일반적인 큐)를 사용하고 있으나,ScheduledThreadPoolExecutor는 자체적으로 큐를 새로 정의해서 사용한다. (DelayedWorkQueue) 해당 큐가 스케쥴링이 가능하게 된 핵심적인 구조이므로, 해당 큐에 대해서는 뒤에서 더 자세히 설명한다.- 또한,
Runnable을 구현한SchduledFutureTask를 큐에 넣어 사용하고 있다.
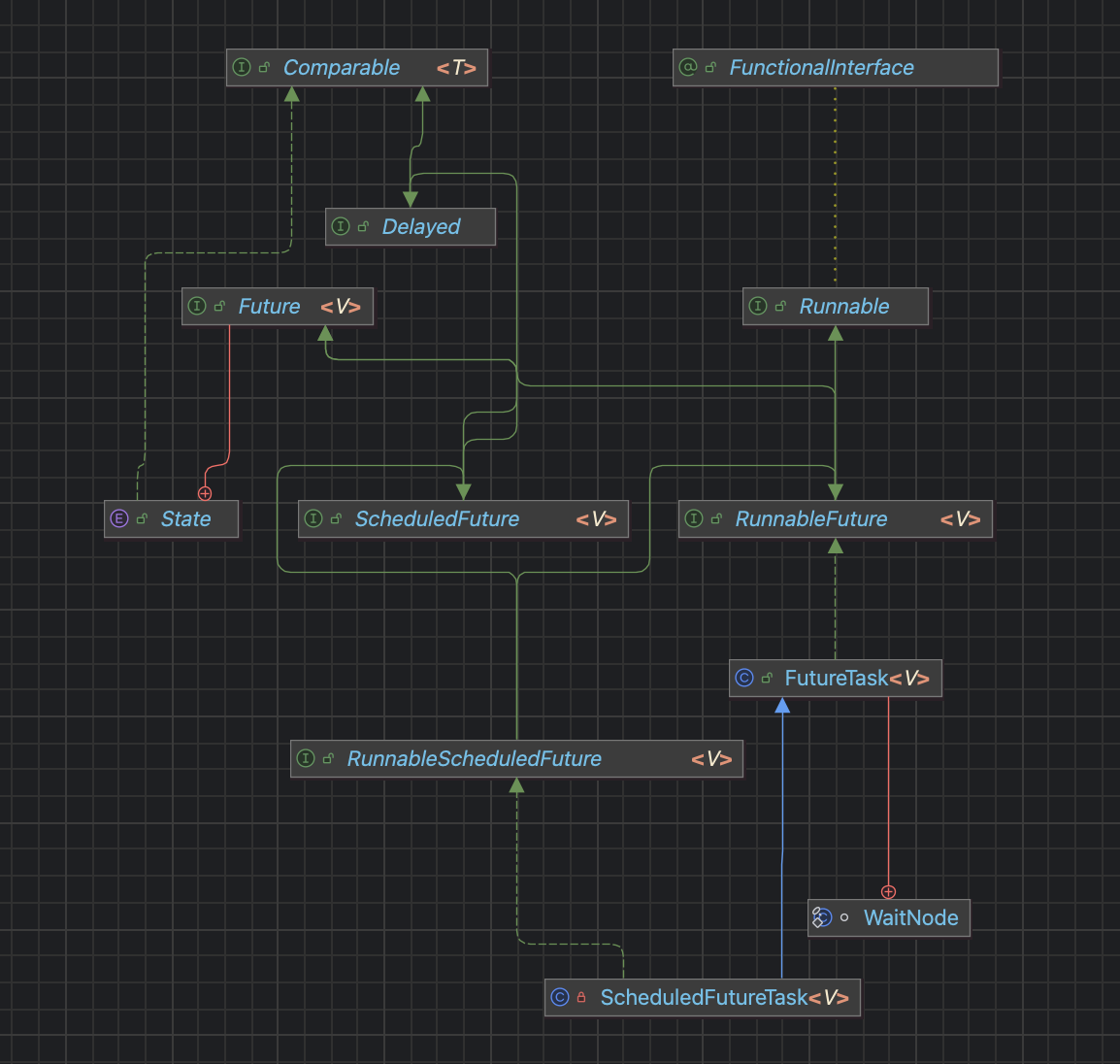
해당 다이어그램은 ScheduledFutureTask 의 구조를 표현한 것이다. 모든 구조에 대해서 이해할 필요는 없고, 전체적인 스케쥴러에 대한 이해를 위해 알아야 할 두 가지 특성만 알고 가도록 하자.
Delayed인터페이스에는getDelay(TimeUnit unit)메서드가 있다. 이는 얼마나 더 기다려야 하는지를 반환하는 메서드이다.RunnableScheduledFuture인터페이스에는isPeriodic()메서드가 있다. 이는 이 작업이 한 번 수행되는 것이 아니라 주기적으로 실행되는지 여부를 반환하는 메서드이다.
저 두 메서드만 봐도, 이게 왜 스케쥴링이 가능한지 이해가 갈 것이다.
이제, 핵심이라고 할 수 있는 DelayedWorkQueue 에 대해 알아보자.
static class DelayedWorkQueue extends AbstractQueue<Runnable> implements BlockingQueue<Runnable> {
/*
* A DelayedWorkQueue is based on a heap-based data structure
* like those in DelayQueue and PriorityQueue, except that
* every ScheduledFutureTask also records its index into the
* heap array.
// 중략
주석에 적힌 heap-based data structure 라는 말에 집중하자. 즉, 자바에서 스케쥴링은 우선순위 큐 기반의 �스케쥴러를 활용하여 수행한다라고 말할 수 있는 것이다.
동작 과정을 조금만 더 살펴보자.
ScheduledThreadPoolExecutor의 Worker Thread 는 기본적인ThreadPoolExecutor의 동작 방식을 따라간다.- 즉, Task를 큐에서 꺼내오고, 있으면 작업을 수행한다.
DelayedWorkQueue는 가장 먼저 수행되어야 하는 작업에 대해 우선순위 큐 형식으로 데이터를 저장하고 있다.- 다만 interface 구조 상 일반
Runnable도 큐에 들어갈 수 있는데, 이렇게 될 경우 delay = 0이고 반복실행이 되지 않는ScheduledFutureTask로 간주한다. (즉, 즉시 실행된다.) - 만약, 같은 타이밍에 수행되어야 하는 작업이 있다면, 이는 FIFO 로 처리된다. (내부적으로 순서를 기록하기 위한
AtomicLong sequencer를 포함하고 있다.) - Task가 있음에도 큐의 맨 앞에 있는 Task의 수행되어야 하는 시점이 현재 시점보다 과거라면, (다시 말해서 우선순위 큐에 의해 가장 빨리 시작되어야 하는 것으로 판단된 Task가 현재 시점 뒤에 수행되야 한다면) null 을 반환한다. 즉, 큐에 아무것도 없는 것으로 처리한다. (
Queue.poll()수행 기준)
- 다만 interface 구조 상 일반
- Worker Thread 는 기본적으로 큐에서 데이터를 소비하려 하며, 만약 데이터가 없다면 Queue의
poll(keepAliveTime, TimeUnit.NANOSECONDS)이나take()를 수행한다.DelayedWorkQueue는 해당 메서드를 수행할 경우 스레드를Condition.await()를 통해 sleep 시켜버리고, 새로운 데이터가 들어오는 순간Condition.signal()을 통해 깨운다.- 이를 통해, Spin Lock 같은 방식을 사용하지 않고도 스레드를 대기시�킬 수 있으며, 자연스럽게 Task를 수행할 수 있다.
물론 위 내용만 읽어본다면, 해결되지 않는 의문이 여전히 존재한다.
DelayedWorkQueue에 현재 시점보다 10초 뒤에 수행해야 할 Task를 넣었다고 가정하자.- Worker Thread는 Task를 가져오려 하나, 큐에 데이터가 없는 것으로 판단되어 await가 될 것이다.
- 그렇다면 누가 깨우지...??
사실 이는, Queue를 상속한 BlockingQueue에는 take() 라는 메서드가 추가로 존재한다 라는 사실을 알아야 이해할 수 있다.
Queue.poll()- 데이터를 가져온다. 없으면 null을 반환한다.BlockingQueue.take()- 데이터를 가져오려 시도한다. 없으면 데이터를 가져올 수 있을 때 까지 블로킹된다.
그렇기 때문에, DelayedWorkQueue 는 각각의 메서드를 아래와 같이 구현했다.
DelayedWorkQueue.poll()- Task를 가져오되, 만약 맨 앞 Task가 현재 시점 뒤에 수행되어야 하면 null을 반환한다.DelayedWorkQueue.take()- Task를 가져오되, 만약 맨 앞 Task가 현재 시점 뒤에 수행되어야 하면 그 시간 까지 await 되었다가 (awaitNano(nanoSecond)를 통해) task를 가져온다.
물론 실제로는 조금 더 복잡하다. (이미 작업을 수행중인 다른 Worker Thread가 있으면 현재 Thread는 그냥 await 된다거나...) 하지만 이정도만 이해해도, 우리는 충분히 동작 방식을 이해했다고 말할 수 있을 것이다.
이 방법을 통해 효율성을 최대로 높일 수 있으나, 역시 처음 제시한 문제였던 완벽히 정확한 시간에 수행되는 것이 불가하다는 여전히 해결하지 못했다. 다만 이는 일반적인 언어 환경에서는 엄�밀한 수행이 불가능하기 때문에, 이해하고 넘어가도록 하자.
Spring 의 @Scheduled 는?
사실 대부분의 사람들은 위에서 언급한 ScheduledThreadPoolExecutor를 써볼 일이 거의 없겠지만, 반대로 Spring 이 제공하는 @Scheduled는 많이 써봤을 것이다.
뭔가 윗 부분을 꼼꼼하게 읽었다면 Spring 이 제공하는 것도 저걸 사용하지 않았을까? 하는 생각이 들텐데, 과연 진짜인지 확인해보도록 하자.
@EnableScheduling
- 스케쥴링 기능을 활성화 하기 위해 붙이는 메타 어노테이션이다.
- 해당 어노테이션을 붙이게 되면, 자동으로
SchedulingConfiguration.java를 import 하여 사용하게 된다.
SchedulingConfiguration
ScheduledAnnotationBeanPostProcessor를 등록한다.
SchduledAnnotationBeanPostProcessor
- 빈 후처리기 (BeanPostProcessor) 는 Spring Container 에 빈을 등록하기 전, 특정 빈들을 대상으로 추가 작업을 해주는 Processor 이다.
@Scheduled,@Schedules어노테이션이 붙은 메서드들이 캡쳐 대상이며, 해당 설정을 파싱하여Runnable과Trigger형태로 변경한다.- Spring 이 자체적으로 스케쥴링을 추상화 한 인터페이스인
TaskScheduler에 정보를 전달하며, 주로 기본 구현체인ThreadPoolTaskScheduler를 사용한다. - 그런데,
ThreadPoolTaskScheduler는ScheduledExecutorService를 갖고 있으며, 해당 인터페이스의 구현체가 위에서 설명한ScheduledThreadPoolExecutor이다. - 추가적으로, Cron Job의 경우 내부적으로
CronTrigger를 갖고 있는데, 이는 다음 실행 시점을 계산하여 주기적으로 큐에 들어갈 수 있도록 도와준다.
결국 돌고 돌아, 기본적인 원리는 위에서 설명한 것과 동일한 것이다. 다만 사용성을 높이기 위해 많은 사항이 추상화 되어 있고, 그렇기에 이를 사용하는 우리 입장에선 아무 내용도 몰라도 문제 없이 사용할 수 있는 것이다.
하지만 내부 구조를 알고 있으니, 우리는 @Scheduled를 사용함에 있어 추가적인 가이드라인을 얻을 수 있다.
@Scheduled 사용 시 알 수 있는 것들
-
corePoolSize = 1 이다. 즉, 스케쥴링 잡은 병렬로 수행되지 않는다.
- 내부적으로 스레드풀을 사용하고 있지만, 결국은 스레드가 1개라서 작업은 모두 순차적으로 수행된다.
- 앞서 동일한 타이밍에 수행되어야 하는 Task가 여러 개라면, FIFO 형식으로 수행된다 했으나, 빈 후처리기에 들어가는 순서를 완벽하게 조정하는 것은 쉽지 않기 때문에, (여러 변수가 존재하므로) 결국 같은 시간에 수행되어야 하는 Task는 순서를 보장하기 어렵다.
- 병렬 처리를 원한다면, Configuration 으로 새로운
ThreadPoolTaskScheduler를 재정의해야 한다.
-
queueSize 는 제한이 없다. 즉, 아무리 많은 스케쥴링 잡이라도 일단 넣을 수는 있다.
- 당연히 너무 많으면 문제가 될 수 있겠지만, 구성상 그렇게 많은 작업을 수행하기 어려우므로, 특별하게 조정하지 않아도 문제는 없다.
-
Scheduled Task의 다음 실행 시점은 작업이 끝나고 결정된다.
-
앞에서 설명을 하지 않았던 부분이지만,
DelayedWorkQueue가 스케쥴링 대상으로 쓰는ScheduledFutureTask의run()메서드를 살펴보자. -
public void run() {
if (!canRunInCurrentRunState(this))
cancel(false);
else if (!isPeriodic())
super.run();
else if (super.runAndReset()) {
setNextRunTime();
reExecutePeriodic(outerTask);
}
}
private void setNextRunTime() {
long p = period;
if (p > 0)
time += p;
else
time = triggerTime(-p);
} -
super.runAndReset()->setNextRunTime()순으로 수행됨을 볼 수 있다. 즉, 작업이 수행된 이후, 다음 작업이 실행될 타이밍을 계산한다 라고 말할 수 있다. -
Spring
@Scheduled환경에서, 특정 작업을 fixedRate로 등록하게 되면 (시작 시점 + 주기) 로 다음 시간이 계산되는데, 만약 10초가 걸리는 작업을fixedRate = 1000으로 등록했다고 가정 해보자.- 이 경우, 잘 모른다면 10초 동안 해당 작업이 10번 큐에 들어간다고 생각할 수 있지만, 작업이 종료된 후 단 한 번만 계산되기 때문에, 큐에는 1개만 들어가게 된다.
- 다만 이렇게 되면 작업이 종료되고 텀 없이 바로 이어서 작업이 수행되므로, 텀을 확보하고 싶다면
fixedDelay = 1000으로 설정하는게 맞다.
-
참고로, 이와 관련된
ScheduledThreadPoolExecutor의 메서드는 다음과 ��같다.scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit)- (이전 실행 시작 시점) + period 만큼 대기
scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit)- (이전 실행 종료 시점) + period 만큼 대기
-
Spring 을 사용하지 않고 스케쥴링을 구현해야 하는 상황이 발생하여 처음으로 ScheduledThreadPoolExecutor 를 사용해 보고, 동작 원리가 궁금해져 글을 작성하다 보니 다소 글이 길어졌다.
별개로 올해 Spring/JDK 분석 스터디를 개설하려고 고민하고 있는 중이다. 원래는 해당 스터디를 의식하고 작성한 글은 아니었지만, 작성하다보니 스터디의 방식을 이런 식으로 하면 좋겠다는 생각이 들었다.