네트워크의 "연결" 과 관련한 주저리

네트워크의 "연결" 이라는 키워드를 언급하면, 다들 OSI 7계층을 떠올리고, 더 나아가서 TCP에 대해 떠올릴 수 있을 것이다.
솔직히 말해서 기술면접 아니면 그렇게 깊게 다룰일이 없을 것 같았지만... 막상 회사 업무를 하다보면 이런 네트워크적인 이슈가 발생할 때 마다 심심치 않게 언급되는 원인이 연결 자체인 경우가 많았다.
세미나에서도 한 번 언급하기도 했지만, 많은 분들이 회사에 처음 입사하던 나 처럼 (...) 기술면접용으로만 TCP를 다루고 있어서 이 참에 한 번 깊게 파고 들어보자.
또한, 연결이라는 키워드는 7계층에서도 다룰 수 있는 주제인데, 어떤 관점에서 이를 다룰 수 있을지도 알아보자.
소켓부터 살펴보자.
우선, 소켓이 무엇인지부터 생각해 볼 필요가 있다. (취준생 분들이 소켓을 어떻게 이해하는지 궁금해서 구글링을 해봤더니, 심각한 오개념으로 넘쳐나는 글들이 구글 최상단에 있어서 부득이하게 정리해본다.) 다만 글의 목적은 이게 아니므로, 글을 이해할 수 있고, 오개념을 거를 수 있는 수준으로만 알아보자.
정말 짧게 요약하자면, "통신을 위한 인터페이스" 정도로 요약할 수 있다. 인터넷을 통한 외부 네트워크와의 통신이던, 같은 PC 내 서로 다른 프로세스 간의 통신이던 가리지 않고 지원하는 인터페이스라고 보면 된다. (일반적으로 사용하는 BSD Socket 기준)
리눅스의 철학상 당연히 파일이며, 이에 따라 내부적으로 소켓을 구분할 때도 파일 디스크립터를 사용하고 있다. (이후 포스팅으로 작성하겠지만, 파일이기 때문에 각 프로세스가 맺을 수 있는 연결의 수 또한 파일 정책을 적용 받아 제한될 수 있다.)
엔드포인트의 정보를 포함하고 있기 때문에 하나의 연결에 대해 하나의 소켓이 존재하며, 따라서 하나의 프로세스는 동시에 여러 소켓을 가질 수가 있다. (상술했듯이 이 또한 파일이기 때문에, 하나의 프로세스가 여러 파일을 열 수 있다는 걸 생각하면 쉽게 이해할 수 있다.)
크게 분류하자면 Unix Domain Socket, Network Socket (Internet Socket)으로 구분이 가능한데, 아주 짧게만 알아보자.
Network Socket
우리가 흔히 "소켓" 이라고 말하면 떠올리는 것을 의미한다. (이 글의 이후 섹션에서도 해당 Network Socket을 소켓이라고 지칭할 것이다.)
Network Socket의 주 목적은 "우리가 Transport Layer의 내부 구현을 알지 못해도, API 형태로 원하는 방식으로 통신 흐름을 제어하기 위함" 이다. (사실 내부 구현에 대한 이해 없이 원하는 목적을 달성할 수 있도록 하는 것이 API의 목적인건 다들 알죠?)
우리가 일반적으로 "네트워크 통신" 을 한다고 말한다면 99.999%는 내부적으로 소켓을 사용한다. (어쨌거나 소켓은 API 이기 때문에, NIC에 다이렉트로 때려박는 방식을 사용하면 소켓을 안 쓸 수는 있다. DPDK, PF_RING 등의 대안이 있지만, 이건 Network I/O 의 성능을 극한으로 올리기 위해 개발된 도구이고, 웹서버 개발하는 우리의 입장에선 잊어버리는게 좋다.)
생각 이상으로 많은 블로그가 이 개념을 혼동하다보니 생각보다 많은 오해를 하는데...
- 이상할 정도로 많은 블로그가 "HTTP 통신" 과 "소켓 통신" 에 대한 비교를 한다.
- 당연히 HTTP는 7계층 프로토콜이고, 4계층에선 소켓을 쓰기 때문에, 애초에 비교가 불가능하다.
- WebSocket을 보고 소켓이라고 착각하는 것 같은데, WebSocket은 7계층 프로토콜이고, HTTP와 WebSocket 모두 Socket API를 내부적으로 쓰고 있다.
- WebSocket 스펙 자체가 실시간 통신을 구현하기 위해 Socket API를 직접 구현하여 사용하던 이전의 문제를 해결하기 위해 고안된거지, 그래봤자 대신 Socket API를 호출하는건 변함이 없다.
- 다만 프로토콜 스펙의 차이로 인해 HTTP는 데이터 전송 완료 후 TCP 연결을 해제하고, WebSocket은 그렇지 않고 연결을 유지할 뿐��이다.
사실 이 섹션을 읽어보고 고민을 해보면 알겠지만 HTTP "통신" 이라는 말도 어색하다.
- HTTP는 단방향이고 소켓 통신은 양방향이라고 말한다.
- 이 또한 프로토콜 스펙의 차이이다. 4계층의 문제가 아니라 7계층의 문제다.
- Stream Socket은 TCP 이고, Datagram Socket은 UDP 이다.
- Stream Socket을 의미하는
SOCK_STREAM은 바이트 단위의 스트림을 통한 데이터 전송을 하는 소켓인거지, TCP가 아니다.SOCK_DGRAM또한 마찬가지다. - 4계층이 TCP와 UDP만 있는 건 아니기도 하고... TCP/UDP 가 저 형식으로 데이터를 전송하는거지 그 역은 성립하지 않는다.
- ICMP 프로토콜 등의 다른 네트워크 프로토콜도 데이터그램이나, 스트림을 통한 데이터 전송이 가능하므로 해당 소켓을 사용할 수 있다.
- Stream Socket을 의미하는
사실 처음 공부하는 분들이 블로그를 통한 학습을 많이 하는데, 이러다보니 블로그에 적힌 오개념을 무비판적으로 받아들이는 문제가 많은 것 같아서 다소 아쉽다.
Unix Domain Socket
반대로, 운영체제 내에서 서로 다른 프로세스들이 통신하기 위해 사용하는 소켓은 Unix Domain Socket으로 부른다.
localhost:8080 와 같은 방식이랑 무슨 차이이죠?
- localhost:8080은 Network Socket을 사용한다.
- 다만 Loopback address임이 확인되면, 하위 계층으로 내려보내지 않고 중간에 방향을 틀어 애플리케이션을 찾고 올라가긴 한다.
- 성능적으로는 Unix Domain Socket이 더 우수하다. (참고)
하지만 예시를 많이 보지 못했기에, 와닿지 않아 보인다. 물론 많이 쓰고 있지만 사용하는 것 자체를 모르고 있으니 와닿지 않는 것이긴 하다. 아쉽게도 해당 포스트는 Unix Domain Socket에 대한 글이 아니기 때문에, 자세한 설명은 생략한다. (~~.sock 과 같은 확장자를 사용하고 있다면, 그 프로그램/서비스는 UDS를 쓸 확률이 굉장히 높다. 예를 들어, docker.sock, gunicorn.sock, mysql.sock이 있다.)
소켓의 State와 함께 살펴보는 4 Way Handshake
우리가 알고 있는 4-Way Handshake는 다음 그림과 같다.
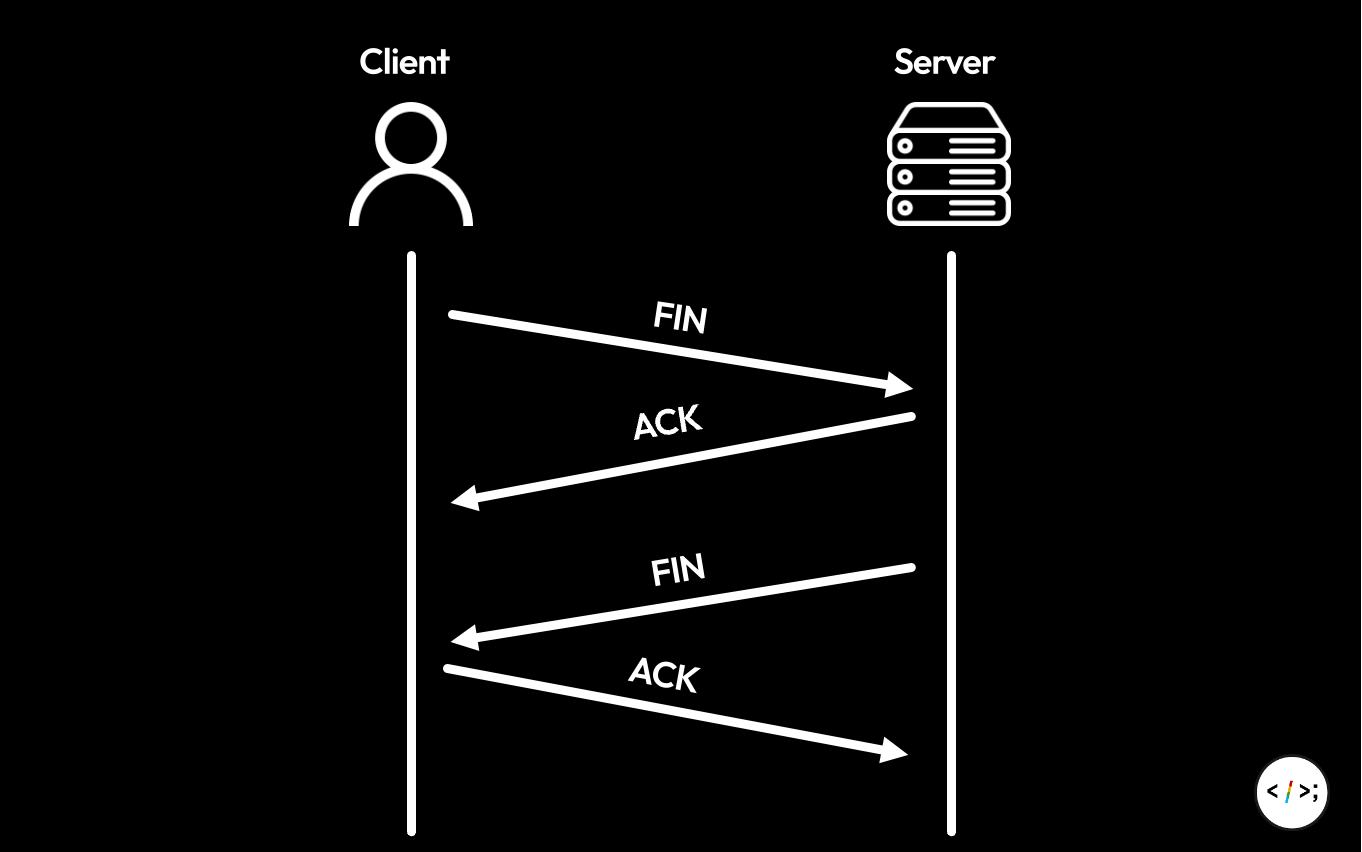
이를 소켓 관점으로 살펴보자.
사실 소켓은 일종의 State를 갖고 있고, 3-Way Handshake와 4-Way Handshake를 수행하는 과정에서 이 State가 변화한다. (실제로 linux 에서는 ss, mac 에서는 netstat 명령으로 존재하는 소켓의 state를 조회할 수 있다.)
따라서 State를 포함하여 위 그림을 다시 그리면 다음과 같다.
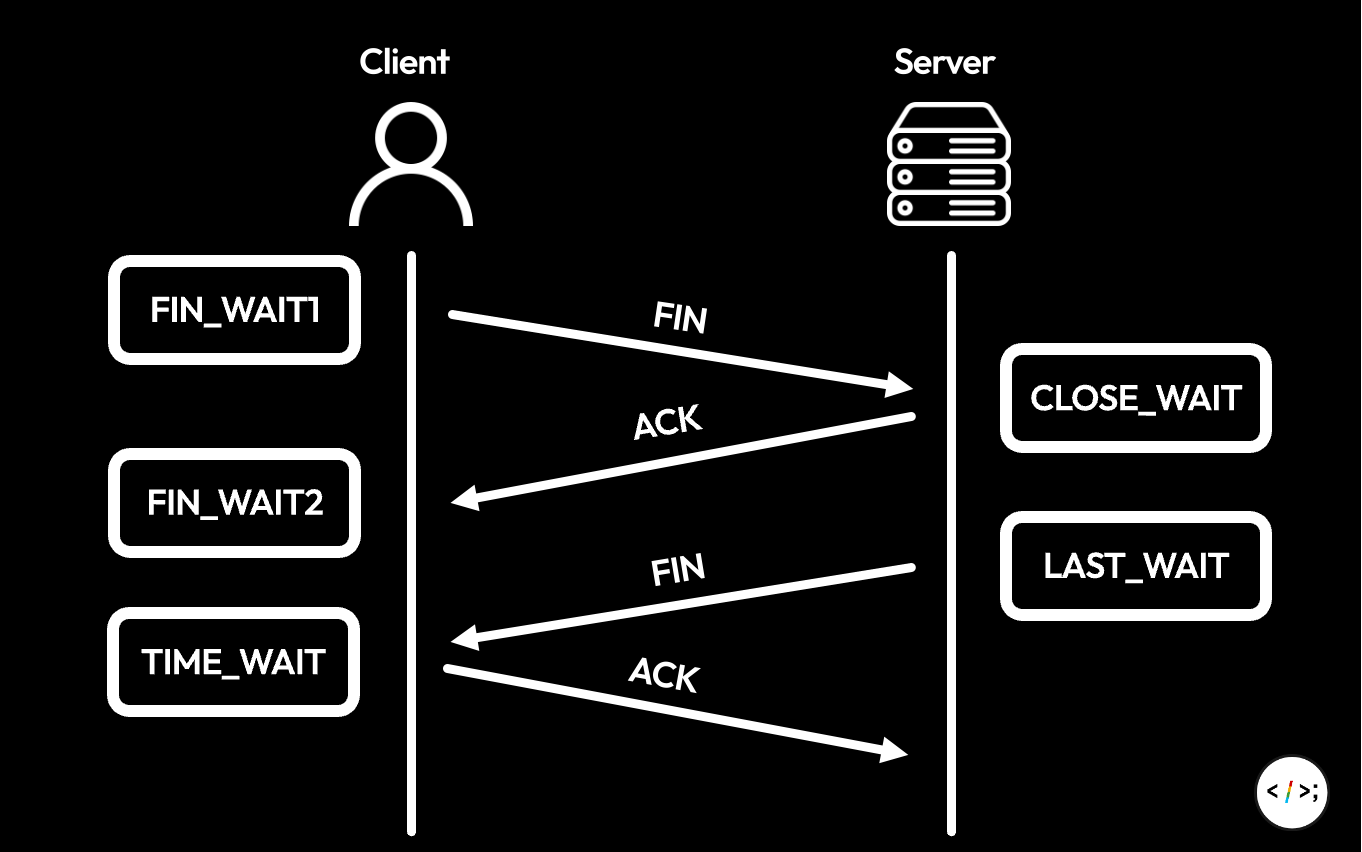
실제로 우리가 사용하고 있는 소켓은 다 특정 State를 갖고 있고, 이 State를 확인하는 것 만으로도 생각보다 많은 이야기를 할 수 있다. (이건 3-Way handshake 부분에서도 정말 할 말이 많다.)
Handshake의 유의점
항상 저 State는 이상적인 경우이다. 진짜 문제는, 전달되는 데이터가 유실될 가능성이 항상 존재한다는 점이다.
이제 Client, Server 라는 말을 사용하지 않고 Active Close, Passive Close 라는 용어를 사용하도록 하자.
- Active Close: 연결을 끊는 주체, 최초
FIN_WAIT상태를 생성하는 주체이다. 위 그림에서는 Client의 역할이다. - Passive Close: 연결 끊는 요청을 받는 대상, ACK 을 받고
CLOSE_WAIT로 상태를 변경하는 주체이다. 위 그림에서는 Server의 역할이다.
왜 이런 용어를 사용해야 하는 걸까? 그 이유는 Nginx와 Spring Boot (Tomcat) 같은 케이스를 생각해보면 된다. 일반적으로 Nginx 를 앞단에 두고, Spring 서버를 뒷단에 두는데, 이 경우에 무엇이 Client이고 무엇이 Server인지 구분할 수 있을까?
데이터 전달에 실패하여 플래그가 전달되지 않은 경우, 상당히 문제가 될 수 있다.
CLOSE_WAIT에서 ACK를 전달하지 않거나, 전달 실패한 경우에는 다소 위험하다.CLOSE_WAIT를 강제로 제거 하는 방법은 애플리케이션 강제 종료 및 네트워크 재시작 말고는 존재하지 않는다. 애초에 이 상태로 멈춰 있는 케이스가 발견되면 틀림없이 애플리��케이션이나 프레임워크에 심각한 버그가 존재하는 것이니, 빠르게 찾아내야 한다.
FIN_WAIT나TIME_WAIT에서 비슷한 문제가 발생한 경우에는 그래도 다소 괜찮은 편이다.- 어쨌거나 둘 다 timeout 이 존재하기 때문에, 병목이 발생하더라도 어쨌거나 자연 해결이 되긴 한다.
- 극단적으로 활용이 필요하다면,
tcp_tw_reuse커널 파라미터를 조정하면TIME_WAIT소켓 재사용이 가능하다.
Passive Close 측면에서 FIN_WAIT 나 TIME_WAIT 는 중요한 이슈가 아니다. (일반적인) 클라이언트 소켓은 내부 포트를 명시해야 하지만, (일반적인) 서버 소켓은 포트가 고정되어 있기 때문에 (웹서버를 생각해보면, LB 또는 특수 목적으로 포트를 분리하는게 아닌 이상 1개로 매핑하고 있으니) 소켓의 수가 많아진다고 포트가 고갈되어 문제가 발생하는 일은 없기 때문이다. (다만, 너무 소켓이 많아지면 open 가능한 file desciptor 의 컷에 걸리지만, 이건 수정하면 된다.)
다만, 서버가 Active Closer 역할을 하는 순간 문제가 좀 꼬일 수 있다. 상술한 Nginx와 Spring (Tomcat) 과의 연결 케이스에서 발생할 수 있는 케이스다.
그래도 걱정할 필요가 없는게, 기본 설정을 바꾸지 않는다면 어지간해선 해당 문제가 발생하지 않으므로 안심해도 된다.
좀 더 찾아보기
원래는 좀 더 하고 싶은 이야기가 많았지만, 하나의 포스트에 담기는 너무나도 내용이 방대해 질 것 같았다. 따라서 이후 내용을 이해할 수 있을 정도로만 설명했으며, 만약 좀 더 관심이 있다면, 그러한 분들을 위해 좋은 글과 책을 소개하고 간다.
- CLOSE_WAIT & TIME_WAIT 최종 분석 (Kakao Tech)
- TCP의 TIME_WAIT를 없애는 법
- Coping with the TCP TIME_WAIT state on busy Linux servers
- DevOps와 SE를 위한 리눅스 커널 이야기
Timeout 살펴보기
Java에서 외부 요청을 보낼 때, 어떻게 네트워크 연결을 수행할까?
이런 내용에 대한 깊은 지식이 있지 않더라도, 이런 외부 네트워크 통신 또한 I/O의 일종이기에 해당 스레드가 "일반적으로는" Blocking 된다는 것은 다들 알고 있을 것이다. (Selector를 사용하면 Non-Blocking I/O가 가능하다는 것을 이전 세미나에서 다루긴 했고, 실제로 Netty 등을 사용하여 Non-Blocking I/O 를 사용하는 경우도 많다.)
그리고 Blocking 여부와는 상관없이, 일반적인 사용자의 요청을 처리하는 과정에선 요청의 응답값을 필요로 하는 경우도 많다보니, Non-Blocking 이라고 하지만 결국에는 결과를 기다려야 하는 케이스가 많을 것이다.
결국은 잘못된 연결을 오래 붙잡고 있으면 이득될 부분이 없기도 하고, 상황에 따라 장애가 전파되는 상황 까지 도달할 수 있으므로 적절하게 연결을 끊을 필요가 있다. 그렇기 때문에, 일반적으로 외부 연결을 시도할 때는 이에 대응하는 Timeout 시간을 지정한다.
- ConnectionTimeout: TCP Handshake 과정에서의 timeout
- readTimeout: 형성된 세션을 통해 데이터를 주고 받는 과정에서의 timeout (다만, 전체 통신 시간이 아닌, 특정 데이터 전송 시간이라고 보면 좋다.)
물론 모두가 저런 이름을 사용하지 않는 경우도 있다.
- JDBC Driver 계열은 (ex. MySQL JDBC Driver) 대부분 readTimeout 이 존재하지 않는다. 다만 SocketTimeout이 존재하는데, 일부 드라이버가 SocketTimeout 의 내부 구현을 readTimeout 과 유사하게 사용하고 있다.
- 추가적으로, 애플리케이션 (ex. mybatis, spring) 은 statementTimeout이 따로 존재한다. 이는 쿼리의 수행시간에 대한 timeout으로, 데이터 전송 시간이 포함된 socketTimeout 보다 작게 잡는 것이 좋다.
- 우리가 사용하는 쿼리의 목적에 따라 statementTimeout 을 다르게 잡는 것도 좋다.
참고를 위해서, 간단한 예시를 남기고 간다. 아직까지 connectionString 에 timeout 을 지정해보지 않았다면, 이 참에 적극적으로 고려해보자.
mongodb://db.asdf.com:27017/database?connectTimeoutMS=3000&socketTimeoutMS=5000&minPoolSize=64&maxPoolSize=256&waitQueueTimeoutMS=1000&w=1&wtimeoutMS=3000&retryWrites=true&readPreference=primary&readConcernLevel=local
Timeout 과 관련한 정보가 더 필요하다면, 다음 글을 참조하면 좋다.
Case Study
Stale Connection
일반적인 스프링 서버에서는 연결을 매번 생성하지 않고, Connection Pool을 생성하고 해당 Pool 안에 수많은 Connection 을 포함하는 방식으로 연결을 구성한다.
그런데 상대방 (ex. DBMS) 이 연결을 끊어버렸다면? 또는 DBMS 에러에 의해 연결 자체가 의미가 없어진다면? 정상적인 종료가 이뤄지지 않았다면, 당연히 그 연결은 의미가 없어진다. 이 과정에서 이걸 어떻게 처리하냐가 중요한 이슈가 될 수 있다.
- 해당 연결만 문제라면 다른 Connection 을 가져와서 처리하면 된다.
- 다만, DB 전체가 문제가 생겼다면 Connection 이 전체적으로 의미가 없어진다. 이 경우에는 빠르게 에러 처리를 하고, 연결이 가능할 때 다시 Connection Pool을 채워줘야 한다.
만약 Connection 을 가져오지 않고 그냥 에러를 띄워버린다면, 서비스에 영향이 갈 정도로 에러가 자주 발생할 수 있는 위험이 존재한다. 따라서, 거의 대부분의 Connection Pool은 이러한 구조를 띄고 있다.
이와 관련하여 더 많은 정보가 필요하다면, 다음 글을 살짝 읽어보면 좋다.
Proxy/Load Balancer
이 부분을 이해하려면 TCP Keepalive 에 대한 이해가 있어야 합니다. (HTTP Keepalive 와 헷갈리면 안 됩니다!)
트래픽이 많아지거나, 클라우드 환경으로 이어지면서 클라이언트가 서버로 직접 연결하는 것이 아닌, 프록시나 로드밸런서를 통해 Indirect 하게 연결을 하는 케이스가 많아지고 있다.
데이터를 전송하는 케이스를 생각해보자.
- 클라이언트는 서버로 요청을 하기 위해, 주어진 IP로 요청을 보낸다.
- IP는 LB를 향해 있고, LB를 통해 요청을 보낸다.
- LB는 요청을 받아 서버로 전달한다.
이 때, 서버의 데이터는 어떻게 클라이언트에게 전달되어야 할까?
- 서버 -> 로드밸런서 -> 클라이언트로 전달되어야 하는가?
- 아니면, 서버 -> 클라이언트로 전달되어야 하는가?
당연하겠지만, 일반적으로 요청보다는 응답의 크기가 훨씬 큰 편이다. (사용자는 HTTP 요청 하나만 보내지만, 응답은 거대한 이미지라고 가정 해보자. 답이 뻔하다!) LB가 여러 서버에서 전달되는 거대한 응답들을 다 받아야 하는가?
그렇기에, 생각보다 많은 케이스에서 요청은 클라이언트 -> LB -> 서버로 향하지만, 응답은 서버 -> 클라이언트 로 전달되는 경우가 많다. 우리는 이를 DSR (Direct Server Routing) 이라고 호칭한다.
자, 이제부터 문제를 잘 살펴보자.
- 로드밸런서나 프록시는 일반적으로 반복되는 사용자의 요청을 동일한 서버로 매핑하려고 한다. 그렇기에, 세션 테이블을 만들어 클라이언트와 서버간의 매핑을 저장하고 있다.
- 이는 Idle timeout으로 관리되며, 해당 시간 동안 클라이언트에게 요청이 오지 않을 시 테이블의 정보를 제거한다.
- 앞에서 우리는 응답이 서버 -> 클라이언트에게 전달된다고 했다. 그 말뜻은...
- TCP 3-Way Handshake가 진행되면, 처음에는 클라이언트 -> LB -> 서버와 같은 식으로 SYN이 보내진다.
- 이후 서버 -> 클라이언트 식으로 SYN + ACK 가 생성될 것이다.
- TCP Keepalive 에 의해, 클라이언트와 서버가 Handshake가 이루어지면 연결이 끊어지지 않고 지속적으로 유지된다.
- 이 과정에서, TCP Keepalive 에 의해 연결이 끊어지지 않았는데 IdleTimeout에 도달해서 세션 테이블 데이터가 제거되었다면??
- 클라이언트는 해당 서버 접속이 필요해서 요청을 보냈는데, LB의 세션 테이블에는 데이터가 존재하지 않아 새롭게 매핑을 진행한다.
- 이 때, 사실상 랜덤으로 목적지 서버가 결정되므로, 상황에 따라 처음 연결한 서버가 아닌 다른 서버로 매핑될 수 있다.
- 이 경우, 할당된 서버는 Handshake 없이 갑자기 요청이 들어왔으므로 요청을 거부하고, (이에 따라 RST 패킷 전송) 결국 새롭게 연결을 생성해야 한다.
- 이 모든 과정이 애플리케이션 입장에선 Connection 수립 과정이므로, 클라이언트는 Connection Timeout을 띄우고 오류를 발생시킬 수 있다.
- 클라이언트는 해당 서버 접속이 필요해서 요청을 보냈는데, LB의 세션 테이블에는 데이터가 존재하지 않아 새롭게 매핑을 진행한다.
그렇기 때문에, 중간에 프록시를 띄우거나 LB를 띄우는 경우, 클라이언��트나 프록시/LB 의 timeout 설정을 다소 신중하게 잡을 필요가 있다.
- nginx 는 TCP keepalive, HTTP keepalive 에 대한 설정을 제공하고 있다. 대상 서버가 nginx를 사용하고 있다면, 일차적으로 해당 설정 변경을 고려해야 한다.
- 다양한 MQ (RabbitMQ, Kafka 등) 또한 기본적으로 TCP Keepalive 에 대한 설정을 포함하고 있다. 필요하다면, 해당 설정값을 변경 할 수 있다.
결론
솔직히 위의 내용들을 취준생 레벨에서 고민하고, 사용하는 것은 매우 어렵다. (실제로 이런 이슈가 문제가 되는 건 대부분 1~2 초간의 타이밍에서 발생하는 문제라, 꾸준히 요청이 들어오는 것이 아니면 감지 자체가 어렵기 때문에)
다만, 항상 주장하는 것 처럼 암기식의 CS가 아니라, 문제 해결을 위해 사용될 수 있다는 것을 이해할 수만 있다면, 충분할 것 같다.